
| Главная | Новости | Framework .NET | Самоучитель C# | Учебники | О сайте |
|
Некоторые сведения об архитектуре Windows
В тексте этого урока использованы материалы, любезно предоставленные преподавателем СПбГТУ Мариной Полубенцевой, с которой мы совместно ведем курс Visual C++ в Microsoft Certified Educational Center при Санкт-Петербургском государственном техническом университете (www.Avalon.ru). Разработчики Windows-приложений живут в особом мире событий и сообщений, в котором последовательность выполнения операций не всегда строго предсказуема. Они выработали свое особое представление о том, как правильно ставить и решать задачи в виртуальном мире операционной системы, управляемой событиями. Если вы, читатель, выполнили все шаги по разработке традиционного Windows-приложения, описанные в третьем уроке этой книги, то, вероятно, уже имеете понятие о структуре и принципе функционирования любой Windows-программы. Традиционным называется приложение, созданное на основе функций API (Application Programming Interface) или программируемого интерфейса приложений. API — это подсистема Windows, которая помогает программировать, то есть планировать и создавать, графический интерфейс пользователя. В состав API, как вы знаете, входят не только функции, но и множество структур языка С, сообщений Windows, макросов и интерфейсов. В последнее время в компьютерном мире обрел популярность термин layer (уровень или слой). Так, различают аппаратный уровень (hardware layer), устойчивый программный уровень (firmware layer) и просто программный уровень (software layer). Примечание Термин firmware обозначает системные процедуры, хранимые в постоянной памяти (ROM) и поэтому не разрушаемые при выключении основного питания. Там обычно хранятся инициализирующие (startup) процедуры, а также низкоуровневые команды ввода-вывода. В смысле простоты внесения изменений уровень firmware занимает промежуточное положение между hardware (аппаратные средства) и software (программное обеспечение). Наряду с этим выделяют другие уровни, например уровень операционной системы, уровень прикладной программы или приложения. Базовый или нижний уровень описания компьютера называется платформой. В общеупотребительном смысле этот термин обозначает тип используемого процессора и/или операционной системы. Любая программа, будь то ваша прикладная, компилятор языка C++, операционная система или драйвер устройства — специальная программа, помогающая управлять каким-либо устройством, в конечном счете представляет собой последовательность машинных инструкций или команд процессора. Команды реализованы на аппаратном уровне (hardware). Все разновидности процессоров обладают своей собственной системой команд, которая совместно с архитектурой процессора и операционной системой, в сущности, и образует платформу. Вы знаете, что есть платформы: DEC Alpha, PowerPC (RISC-платформы), MIPS, Macintosh, Intel (x86) и др. Кроме того, говорят о DOS-платформе или платформе Win32. Здесь уже имеют в виду одного производителя операционной системы, но подчеркивают различие в ее архитектуре, а также длине машинного слова (16 или 32 бита). Термин операционная система, так же как и платформа, является фундаментальным понятием, которое используются при описании конкретной технологии, выбранной при проектировании какой-либо компьютерной системы. Операционная система — это комплекс программ, обеспечивающих взаимодействие между тремя сущностями:
Известно, что в каждый момент времени один процессор может выполнять лишь одну машинную команду. Процессор выполняет команды, последовательно выбирая их одну за другой из памяти в порядке возрастания адресов. Программист может нарушить этот порядок, вставив в программу команду условного или безусловного перехода, команду вызова функции или цикла (bne, call, jmp, loop). Операционная система, даже однозадачная, также может вмешаться в эту последовательность и отвлечься — временно оторваться от последовательности команд для выполнения каких-то других более важных, системных команд. Необходимость такой операции, называемой прерыванием, выясняется в процессе выборки очередной команды. Если система обнаруживает, что есть прерывание, то она запоминает в стеке контекст выполняемой программы: адрес текущей команды, ' содержимое регистров АУ, и переходит в режим обработки прерывания, то есть переключается на выполнение другой программы, вызвавшей прерывание. В системе команд существуют также особые, привилегированные инструкции, которые невозможно прервать. Они называются atomic instructions, (вы помните, что атом переводится как неделимый) и используются системой при выполнении критических для целостности системы процедур. В оперативной памяти (RAM), даже в случае однозадачной ОС (операционная система), могут одновременно находиться несколько программ:
В простейшем случае однозадачной ОС, такой как MS DOS, взаимодействие между тремя объектами, увязываемыми ОС, может протекать так, как показано на рис. 12.1.
Рис. 12.1. Диаграмма взаимодействия ОС с прикладной программой Системный модуль, который подготавливает запуск прикладной программы, с тем чтобы вернуть управление обратно после ее завершения, называется program prefix segment. Он, так же как и модуль завершения программы пользователя, занимает определенное время и другие ресурсы системы. Если в процессе выполнения пользовательской прбграмме нужно выполнить какое-либо стандартное действие, например вывести строку символов на принтер, она может обратиться к стандартной подпрограмме, входящей в состав операционной системы. Такие стандартные действия, реализованные в ОС в виде отдельных процедур, принято называть системными сервисами. Обратите внимание на тот факт, что прикладная программа сама определяет момент предоставления ей системного сервиса. Программа при завершении, как вы знаете, может вернуть системе некий код (успех или неудача). Как программа может узнать о наступлении какого-либо события, внешнего по отношению к ней, например такого, как нажатие пользователем клавиши клавиатуры? Существуют два способа: по опросу готовности и с помощью механизма аппаратных прерываний. Клавиатура является устройством, о котором можно программно, анализируя содержимое программно-доступного регистра состояния клавиатуры, узнать, готово ли оно к обмену, то есть нажата ли клавиша. Алгоритм процедуры обмена, соответствующий первому способу, изображен на рис. 12.2. Он обладает тем недостатком, что при ожидании процессор используется неэффективно, то есть простаивает. Второй способ иллюстрируется рис. 12.3. В результате какого-либо события: нажатия клавиши клавиатуры, движения мыши, срабатывания таймера, вырабатывается сигнал. По этому сигналу процессор прерывает выполнение текущей программы, запоминает состояние (контекст) прерванной программы и передает управление программе-обработчику возникшей ситуации.
Рис. 12.2. Алгоритм опроса готовности
Рис. 12.3. Алгоритм обработки аппаратного прерывания Аппаратные прерывания могут возникать в произвольные моменты времени, и они прозрачны для прикладной программы, то есть она не знает, что была прервана в ответ на какое-то событие. Почему необходимо запоминать контекст прерванной программы и не нужно этого делать при вызове внешней функции? В последнем случае контекст не нарушается, так как программист проектирует вызов функции и сам управляет последовательностью действий, например передачей аргументов. В случае прерывания контекст выполняемой программы нарушается и уже сама система должна сделать все, чтобы восстановить текущее состояние прерванной программы, так как прерывание не было запланировано — не входило в намерения программиста. Теперь рассмотрим, как в случае прерывания прикладная программа узнает о том, что была нажата клавиша и какая (рис. 12.4).
Рис. 12.4. Диаграмма асинхронного взаимодействия Обработчик аппаратного прерывания от клавиатуры преобразует код нажатия клавиши в код, понятный прикладной программе (ASCII), и помещает его в буфер. Прикладная программа не реагирует на нажатие клавиши и не замечает вызова обработчика, но когда у нее возникает желание выяснить, нажимал ли пользователь какие-нибудь клавиши, она вызывает системную функцию. Последняя анализирует буфер и, если он не пуст, возвращает код нажатой клавиши или признак того, что буфер пуст. Почти все современные операционные системы (Windows 95, Windows NT, Windows 2000, Unix) поддерживают преимущественную многозадачность {preemptive multi-tasking). Этот термин, который часто переводят как вытесняющая многозадачность, означает, что процесс или, точнее, его поток, который в данный момент активен, имеет преимущество перед другими конкурирующими потоками с одинаковым приоритетом. Системы Windows 3.1 и Macintosh поддерживают кооперативную многозадачность {cooperative multi-tasking), в которой все управление отдано системе. В такой системе легче программировать, но она менее эффективна. Основным признаком многозадачной ОС является способность совмещать выполнение нескольких прикладных программ. Большое значение при этом имеет способ совмещения, то есть на каком уровне или как конкретно реализовано совмещение. Если однопроцессорная, но многозадачная, система выделяет каждой прикладной программе определенный квант времени {lime slice), спустя который она переключается на выполнение следующей программы, то это система с разделением времени {time-sharingsystem). Системы с разделением времени появились в начале 60-х. Они управлялись main /rame-компьютерами, обслуживающими многочисленные удаленные терминалы. В качестве терминалов сначала использовались обычные телетайпы, которые умели только вводить или выводить информацию. Благодаря огромной разнице в скорости работы таких устройств, как телетайп и процессор, системы с разделением времени успевали переключаться между многими терминалами и вводить или выводить информацию так, что каждому пользователю казалось, что он единолично управляет удаленным процессором. Затем появились персональные компьютеры, которые стали использоваться в качестве удаленных терминалов. В связи с этим для операционной системы главного процессора (например, IBM-370) отпала необходимость заниматься посимвольным вводом-выводом. Теперь акцент в разработке операционных систем был перенесен на управление выполняемыми программными модулями, принадлежащими разным пользователям и одновременно находящимися в памяти главного компьютера. Появились такие понятия, как очередь заданий •-- очередь на обслуживание каким-либо устройством: принтером, плоттером, накопителем на магнитном носителе, приоритет задания, ожидаемое время завершения задания и т. д. В настоящее время, когда каждый пользователь имеет достаточно мощный персональный компьютер, акценты в развитии ОС снова изменились. Теперь большое значение приобретает развитие сетевых, многозадачных ОС. В сущности, теперь пользователь имеет возможность установить на отдельном персональном компьютере многозадачную ОС и разрабатывать приложения, совмещающие вы-полнение нескольких процессов. Каждый процесс, в свою очередь, может состоять из нескольких потоков, выполняемых в адресном пространстве процесса. Первые операционные системы, реализованные на персональных компьютерах, сильно уступали в концептуальном плане и по своим реальным возможностям системам с разделением времени, давно реализованным в mainframe- компьютерах. В Win 16, например, тоже существует понятие многозадачности. Реализовано оно следующим образом: обработав очередное сообщение, приложение передает управление операционной системе, которая может передать управление другому приложению. Такой вид многозадачности, при котором операционная система передает управление от одного приложения другому не в любой момент времени, а только когда текущее приложение отдает управление системе, получил, как было упомянуто, название кооперативной многозадачности (cooperative multi-tasking). Если при таком подходе обработка сообщения затягивается, то пользователь увидит реакцию системы только после завершения обработки текущим приложением • текущего сообщения. Обычно при выполнении длительных операций программист изменяет форму курсора (песочные часы), вызвав API-функцию BeginWaitCursor. Иногда, если это предусмотрел разработчик программы, в таких случаях застрявшее приложение даже вызывает функцию PeekMessage, сообщая системе, что она может обработать очередное сообщение, а текущее приложение способно и подождать. Но главная неприятность при таком подходе заключается в том, что в случае бесконечного цикла, вызванного ошибкой в программе, ОС не имеет шансов получить управление и также зависнет. Пользователю придется перезагружать систему. В Windows начиная с Windows 95 реализован принципиально другой вид многозадачности, в котором операционная система действительно контролирует и управляет процессами, потоками и их переключением. Способность операционной системы прервать выполняемый поток практически в любой момент времени и передать управление другому ожидающему потоку определяется термином preemptive multitasking — преимущественная, или вытесняющая, многозадачность. Реализация ее выглядит так: все существующие в данный момент потоки, часть из которых может принадлежать одному и тому же процессу, претендуют на процессорное время и, с точки зрения пользователя должны выполняться одновременно. Для создания этой иллюзии система через определенные промежутки времени забирает управление, анализирует свою очередь сообщений, распределяет сообщения по другим очередям в пространстве процессов и, если считает нужным, переключает потоки (рис. 12.5). Реализация вытесняющей многозадачности в Windows 2000 дает не только возможность плавного переключения задач, но и устойчивость среды к зависаниям, так как ни одно приложение не может получить неограниченные права на процессорное время и другие ресурсы. Так система создает эффект одновременного выполнения нескольких приложений. Если компьютер имеет несколько процессоров, то системы Windows NT/2000 могут действительно совмещать выполнение нескольких приложений. Если процессор один, то совмещение остается иллюзией. Когда заканчивается квант времени, отведенный текущей программе, система ее прерывает, сохраняет контекст и отдает управление другой программе, которая ждет своей очереди. Величина кванта времени (time slice) зависит от ОС и типа процессора, в Windows NT она в среднем равна 20 мс. Следует отметить, что добиться действительно одновременного выполнения потоков можно только на машине с несколькими процессорами и только под управлением Windows NT/2000, ядра которых поддерживают распределение потоков между процессорами и процессорного времени между потоками на каждом процессоре. Windows 95 работает только с одним процессором. Даже если у компьютера несколько процессоров, под управлением Windows 95 задействован лишь один из них, а остальные простаивают.
Рис. 12.5. Переключение потоков в системе с вытесняющей многозадачностью Различают два способа реализации многозадачности:
Многозадачная (multi-process) система позволяет двум или более программам выполняться одновременно. Многопотоковая (multi-threaded) система позволяет одной программе выполнять сразу несколько потоков одновременно. Современные операционные системы сочетают в себе оба эти свойства. Приложение Win32 может состоять из одного или более процессов. Например, приложение по расчету параметров турбогенератора может состоять из удобной оболочки, написанной на языке C++ (главный процесс), и вычислительных модулей, написанных на языке FORTRAN и запускаемых в виде отдельных (порожденных) процессов. При этом возможен вариант, когда один процесс (модуль программы) занят выводом геометрии расчетной области, а другой одновременно производит расчет электромагнитного поля. Процесс — это понятие, относящееся к операционной системе. Каждый раз, как вы запускаете приложение, система создает и запускает новый процесс. Процесс можно грубо отождествить с ехе-кодом, выполняющимся в отдельном процессоре. С каждым процессом система связывает такие ресурсы, как:
Windows NT/2000 отводит для каждого процесса виртуальное адресное пространство в 4 Гбайт, защищенное от других процессов, которые выполняются в системе в то же самое время. Каждый процесс обязательно создает первичный поток (primary thread) выполнения. Он делает это автоматически и, если программист не предпринимает каких-либо специальных усилий по созданию второго потока, то первичный поток и породивший его процесс обычно отождествляются в сознании пользователя, а , часто и в сознании программиста. Но последний может создать еще один или несколько потоков, которые размещаются в одном и том же адресном пространстве, принадлежащем процессу. Когда они создаются, родительский процесс начинает выполняться не последовательно, а параллельно. Так реализуется потоковая многозадачность. Говорят, что потоки выполняются в контексте процесса. Поток (thread) — это основной элемент системы, которому ОС выделяет машинное время. Поток может выполнять какую-то часть общего кода процесса, в том числе и ту часть, которая в это время уже выполняется другим потоком. Например, код функции, отображающей на экране степень продвижения процесса передачи информации, может одновременно выполняться двумя потоками, которые обслуживают двух клиентов одного сервера. Примечание Сравнительно недавно появилось еще несколько терминов, связанных с этой же тематикой. Нитью (fiber) потока называется выполняемый блок кодов, который «вручную» (manually) прерывается или планируется (scheduled) приложением. Нить выполняется в контексте потока, который ее планирует. Заданием (job object) называется группа процессов, объединенных в общий блок (unit). Задание в ОС имеет свое имя, атрибуты защиты и способность управлять общими (разделяемыми) ресурсами. Операции, производимые системой или программистом над заданиями, воздействуют на все составляющие его процессы. Все потоки (threads) одного процесса пользуются ресурсами породившего их процесса. Кроме того, каждому потоку система и/или программист приписывает приоритет выполнения и набор структур языка С, описывающих контекст потока. Система использует их для запоминания контекста потока, когда его выполнение прерывается. В контекст входят:
Потоки подобны процессам, но требуют меньших затрат при своем создании. Они в меньшей степени, чем процессы, защищены друг от друга, но позволяют совместить выполнение операций и выиграть в общей производительности процесса. Перечислим наиболее типичные случаи, когда следует применять мпогопоточность:
Обычно более эффективной является реализация многозадачности в виде одного процесса с несколькими потоками, чем в виде многих процессов с одним потоком, так как:
Если один поток выполняет медленные операции ввода-вывода, а другой выполняет вычисления, используя только процессор, то эффективность процесса, совмещающего два потока, будет значительно выше, чем эффективность двух процессов, выполненных последовательно. Типичным многопотоковым приложением является сервер, обслуживающий многих пользователей. Каждый новый пользователь обслуживается отдельным потоком одного процесса. Вместо ожиданий, которые связаны с дисковыми операциями, система может перейти к выполнению другого потока. Однако в случае ошибочного проектирования потоки могут и ухудшить общий показатель эффективности процесса. Например, время выполнения процесса с двумя потоками будет ниже, чем эффективность двух последовательных однопо-токовых процессов, если оба потока выполняются в памяти и не требуют интерфейса с пользователем. Система вынуждена постоянно прерывать эффективно работающие потоки и переключаться между ними. Эти переключения ведут к ненужным потерям или лишним операциям (overheads) по загрузке в память и последующей выгрузке структур данных, необходимых для обслуживания потоков. Наличие пользовательского интерфейса приводит к тому, что указанные действия выполняются во время неизбежных пауз, связанных с операциями ввода-вывода, что создает иллюзию совмещения во времени. Создание многопотоковых процессов требует тщательного предварительного анализа с тем, чтобы должным образом скоординировать действия операционной системы и других программных компонентов. Отслеживание состояний многочисленных потоков требует значительных временных затрат, поэтому следует помнить, что Win32-API предоставляет и другие средства реализации асинхронное™ выполнения операций. Например: асинхронный ввод-вывод (I/O), специальные порты I/O (completion ports), асинхронные вызовы удаленных процедур (asynchronous procedure calls — АРС), функции ожидания системных событий (wait functions). Совместный доступ потоков к разделяемым ресурсам: описателям файлов, портов, глобальным переменным, может создать конфликты. Например, один поток читает данные, а другой пытается одновременно их изменить или один поток ждет завершения определенной операции другим потоком, а тот, в свою очередь, ждет отработки первого потока. Такое зацикливание называется тупиковой ситуацией (deadlock). Для предупреждения конфликтов такого рода существуют специальные синхронизирующие объекты ядра системы:, семафоры, мьютексы, события. Часть ОС, называемая системным планировщиком (system scheduler), управляет переключением заданий, определяя, какому из конкурирующих потоков следует выделить следующий квант времени процессора. Решение принимается с учетом приоритетов конкурирующих потоков. Множество приоритетов, определенных в ОС для потоков, занимает диапазон от 0 (низший приоритет) до 31 (высший приоритет). Нулевой уровень приоритета система присваивает особому потоку обнуления свободных страниц. Он работает при отсутствии других потоков, требующих внимания со стороны ОС. Ни один поток, кроме него, не может иметь нулевой уровень. Приоритет каждого потока определяется в два этапа исходя из:
Комбинация этих параметров определяет базовый приоритет (base priority) потока. Существует шесть классов приоритетов для процессов:
Два класса (BELOW... и ABOVE...) появились начиная с Windows NT 5.0. По умолчанию процесс получает класс приоритета NORMAL_PRIORITY__CLASS. Программист может задать класс приоритета создаваемому им процессу, указав его в качестве одного из параметров функции CreateProcess. Кроме того, существует возможность динамически, во время выполнения потока, изменять класс приоритета процесса с помощью API-функции SetPriorityClass. Выяснить класс приоритета какого-либо процесса можно с помощью API-функции GetPriorityClass. Процессы, осуществляющие мониторинг системы, а также хранители экрана (screen savers) должны иметь низший класс (IDLE...), чтобы не мешать другим полезным потокам. Процессы самого высокого класса (REALTIME...) способны прервать даже те системные потоки, которые обрабатывают сообщения мыши, ввод с клавиатуры и фоновую работу с диском. Этот класс должны иметь только те процессы, которые выполняют короткие обменные операции с аппаратурой. Если вы пишете драйвер какого-либо устройства, используя API-функции из набора DDK (Device Driver Kit), то ваш процесс может иметь класс REALTIME... С осторожностью следует использовать класс HIGH_PRIORITY_CLASS, так как если поток процесса этого класса подолгу занимает процессор, то другие потоки не имеют шанса получить свой квант времени. Если несколько потоков имеют высокий приоритет, то эффективность работы каждого из них, а также всей системы резко падает. Этот класс зарезервирован для реакций на события, критичные ко времени их обработки. Обычно с помощью функции SetPriorityClass процессу временно присваивают значение HIGH..., затем, после завершения критической секции кода, его снижают. Применяется и другая стратегия: создается процесс с высоким классом приоритета и тотчас же блокируется — погружается в сон с помощью функции Sleep. При возникновении критической ситуации поток или потоки этого процесса пробуждаются только на то время, которое необходимо для обработки события. Теперь рассмотрим уровни приоритета, которые могут быть присвоены потокам процесса. Внутри каждого процесса, которому присвоен какой-либо класс приоритета, могут существовать потоки, уровень приоритета которых принимает одно из семи возможных значений:
Все потоки сначала создаются с уровнем THREAD_PRIORITY_NORMAL. Затем программист может изменить этот начальный уровень, вызвав функцию SetThreadPriority. Типичной стратегией является повышение уровня до ...ABOVE_NORMAL или ...HIGHEST для потоков, которые должны быстро реагировать на действия пользователя по вводу информации. Потоки, которые интенсивно используют процессор для вычислений, часто относят к фоновым. Им дают уровень приоритета ...BELOW_NORMAL или ...LOWEST, так чтобы при необходимости они могли быть вытеснены. Иногда возникает ситуация, когда поток с более высоким приоритетом должен ждать поток с низким приоритетом, пока тот не закончит какую-либо операцию. В этом случае не следует программировать ожидание завершения операции в виде цикла, так как львиная доля времени процессора уйдет на выполнение команд этого цикла. Возможно даже зацикливание — ситуация типа deadlock, так как поток с более низким приоритетом не имеет шанса получить управление и завершить операцию. Обычной практикой в таких случаях является использование:
Для определения текущего уровня приоритета потока существует функция GetThreadPriority, которая возвращает один из семи рассмотренных уровней. Базовый приоритет потока, как было упомянуто, является комбинацией класса приоритета процесса и уровня приоритета потока. Он вычисляется в соответствии с таблицей, которая довольно объемна (47 строк) и поэтому здесь не приводится. Просмотрите ее в справке (Help), в разделе Platform SDK-Scheduling Priorities (Платформа, SDK-Планирование приоритетов). К примеру, первичный поток процесса с классом HIGH_PRIORITY_CLASS по умолчанию получает начальное значение уровня приоритета THREAD_PRIORITY_NORMAL. Эта комбинация образует базовый уровень приоритета, равный 13. Если впоследствии вы присвоите потоку с помощью функции SetThreadPriority уровень...ьоиЕЗТ, то эта комбинация задаст базовый уровень 11. Если же вы для потока выберете уровень ...IDLE, то базовый уровень скакнет и опустится до единицы. Считая, что класс приоритета процесса не изменяется и остается равным HIGH_PRIORITY_CLASS, сведем все семь возможных вариантов в табл. 12.1. Таблица 12.1. Приоритеты потоков
Планировщик ОС поддерживает для каждого из базовых уровней приоритета функционирование очереди выполняемых или готовых к выполнению потоков (ready threads queue). Когда процессор становится доступным, то планировщик производит переключение контекстов. Здесь можно выделить такие шаги:
Примечание Если в системе за каждым процессором закреплен хотя бы один поток с приоритетом 31, то остальные потоки с более низким приоритетом не смогут получить доступ к процессору и поэтому не будут выполняться. Такая ситуация называется starvation. Различают потоки, не готовые к выполнению. Это:
Блокированные таким образом потоки или подвешенные (suspended) потоки не получают кванта времени независимо от величины их приоритета. Типичными причинами переключения контекстов являются следующие:
В последнем случае система не ждет завершения кванта времени и отнимает управление, как только поток впадает в ожидание. Возможный вариант развития событий изображен на рис. 12.6. Кроме рассмотренного базового уровня каждый поток обладает динамическим приоритетом. Под этим понятием скрываются временные колебания уровня, которые вызваны планировщиком. Он намеренно вызывает такие колебания, для того чтобы убедиться в управляемости и реактивности потока, а также для того, чтобы дать шанс потокам с низким приоритетом. Система никогда не подстегивает потоки, приоритет которых итак высок (от 16 до 31). Когда пользователь работает с каким-то процессом, то он считается активным (foreground), а остальные процессы — фоновыми (background). При ускорении потока (priority boost) система действует следующим образом: когда процесс с нормальным классом приоритета «выходит на сцену» (is brought to the foreground), он получает ускорение.
Рис. 12.6. Вытеснение потока с более низким приоритетом Примечание Термин foreground обозначает то качество процесса, которое характеризует — его с точки зрения связи с активным окном Windows. Foreground window — это окно, которое в данный момент находится в фокусе и, следовательно, расположено поверх остальных. Это состояние может быть получено как программным способом (вызов функции SetFocus), так и аппаратно (пользователь щелкнул окно). Плакировщик изменяет класс процесса, связанного с этим окном, так чтобы он был больше или равен классу любого процесса, связанного с background-окном. Класс приоритета вновь восстанавливается при потере процессом статуса foreground. Отметьте, что в Windows NT/2000 пользователь может управлять величиной ускорения всех процессов класса NORMAL_PRIORITY с помощью панели управления (команда System, вкладка Performance, ползунок Boost Application Performance). Когда окно получает сообщение типа WM_TIMER, WM_LBUTTONDOWN или WM_KEYDOWN, планировщик также ускоряет (boosts) ноток, владеющий этим окном. Существуют еще ситуации, когда планировщик временно повышает уровень приоритета потока. Довольно часто потоки ожидают возможности обратиться к диску. Когда диск освобождается, блокированный поток просыпается и в этот момент система повышает его уровень приоритета. После ускорения потока планировщик постепенно снижает уровень приоритета до базового значения. Уровень снижается на одну единицу после завершения очередного кванта времени. Иногда система инвертирует приоритеты, чтобы разрешить конфликты типа deadlock. Благодаря динамике изменения приоритетов потоки активного процесса вытесняют потоки фонового процесса, а потоки с низким приоритетом все-таки имеют шанс получить управление. Представьте такую ситуацию: поток 1 с высоким приоритетом вынужден ждать, пока поток 2 с низким приоритетом выполняет код в критической секции. В это же время готов к выполнению поток 3 со средним значением приоритета. Он получает время процессора, а два других потока застревают на неопределенное время, так как поток 2 не в состоянии вытеснить поток 3, а поток 1 помнит, что надо ждать, когда поток 2 выйдет из критической секции. Отметьте, что планировщик не способен провести анализ подобной ситуации и решить проблему. Он видит ситуацию только в свете существования двух готовых (ready) потоков с разными приоритетами. Windows NT/2000 разрешает эту ситуацию так. Планировщик увеличивает приоритеты готовых потоков на величину, выбранную случайным образом. В нашем примере это приводит к тому, что поток с низким приоритетом получает шанс на время процессора и, в течение, может быть, нескольких квантов закончит выполнение кодов критической секции. Как только это произойдет, поток 1 с высоким приоритетом сразу получит управление и сможет, вытеснив поток 3, начать выполнение кодов критической секции. Windows 95 разрешит эту ситуацию по-другому. Она определяет факт того, что поток 1 с высоким приоритетом зависит от потока 2 с низким приоритетом, и повышает приоритет второго потока до величины приоритета первого. Это приводит к тому, что поток 3 вытесняется потоком 2 и он, закончив выполнение кодов критической секции, пропускает вперед ждавший поток 1. В системе Windows NT/2000 программист имеет возможность управлять процессом ускорения потоков с помощью API-функций SetProcessPriorityBoost (все потоки данного процесса) или SetThreadPriorityBoost (данный поток) в пределах, которые обозначены на рис. 12.7. Функции GetProcessPriorityBoost и GetThreadPriorityBoost позволяют выяснить текущее состояние флага.
Рис. 12.7. Диапазон изменения приоритета потока При наличии нескольких процессоров Windows NT применяет симметричную модель распределения потоков по процессорам (symmetric multiprocessing SMP), Это означает, что любой поток может быть направлен на любой процессор, но программист может ввести некоторые коррективы в эту модель равноправного распределения. Функции SetProcessAffinityMask и SetThreadAffinityMask позволяют указать предпочтения в смысле выбора процессора для всех потоков процесса или для одного определенного потока. Потоковое предпочтение (thread affinity) вынуждает систему выбирать процессоры только из множества, указанного в маске. Существует также возможность для каждого потока указать один предпочтительный процессор. Это делается с помощью функции SetThreadidealProcessor. Это указание служит подсказкой для планировщика заданий, но не гарантирует строгого соблюдения. Архитектура памяти, используемая операционной системой, — ключ к пониманию того, что в ней происходит. Не имея представления о ней, невозможно ответить на такие вопросы:
Как известно, объем адресуемой памяти определяется размером регистра команд, который обычно зависит от длины машинного слова. Во времена, когда эта длина была равна 16 битам, можно было без особых ухищрений обратиться к любому байту из диапазона (0, 216-1), или 65536 = 64 Кбайт. Обращение к адресам памяти вне этого диапазона стоило определенных усилий. Затем, как вы помните, длина регистра команд стала равной 20 битам и появилась возможность адресовать память в диапазоне (0, 220-1) или 1 048 576 = 1 Мбайт. Правда из-за того, что длина машинного слова оставалась равной 16 битам, приходилось иметь дело с сегментами памяти по 64 Кбайт, базой, смещением, сдвигами и т. д. Теперь, когда наконец длина машинного слова и регистра команд стали равными 32 битам, мы можем свободно адресовать любой байт из диапазона (0, 232-1), или 4 294 967 296 = 4 Гбайт. Так как реально мы не имеем такого объема памяти, то нам предлагают научиться жить в виртуальном мире, а точнее, адресном пространстве Windows. В этом мире, как вы знаете, каждый процесс получает свое адресное пространство объемом 4 Гбайт. Корпорация Microsoft обеспечивает эту, реально не существующую, память с помощью механизма подкачки страниц памяти (page swapping), который позволяет использовать часть жесткого диска для имитации оперативной памяти. Конечно, процессор способен работать лишь с настоящей памятью типа RAM, которой ровно столько, сколько вы купили и установили, но вы можете разрабатывать приложения, не задумываясь об этом ограничении, и считать, что каждый процесс обладает пространством в 4 Гбайт. Как только в программе происходит обращение к адресу памяти, который выше реально доступного, операционная система загружает (подкачивает) недостающие данные с жесткого диска в RAM и работает с ними обычным способом. В MS-DOS и 16-битной Windows все процессы располагаются в едином адресном пространстве, и поэтому любой процесс может считывать и записывать любой участок памяти, в том числе и принадлежащий другому процессу или операционной системе. В таком мире состояние процесса и его благополучие зависят от поведения других процессов. В Win32 память, отведенная другим процессам, скрыта от текущего потока и недоступна ему. В Windows NT/2000 память самой ОС скрыта от любого выполняемого потока. В Windows 95 последнее свойство не реализовано, поэтому в ней текущий поток может испортить память, принадлежащую ОС. Итак, адресное пространство процесса — это его частная собственность, которая неприкосновенна/Поэтому первичные потоки всех процессов, одновременно существующих в физической памяти, загружаются с одного и того же адреса. В Windows NT/2000 — это 0x00400000 (4 Мбайт). Такое возможно только в виртуальном мире, в котором реальные адреса физической памяти не совпадают с виртуальными адресами в пространстве процесса. Как система отображает виртуальные адреса в реальные? Оказывается, что Windows 95 делает это не так, как Windows NT/2000. Мы будем рассматривать только последний случай, так как первый хоть и отличается от него, но эти отличия могут заинтересовать лишь ограниченный контингент разработчиков, ориентированных на разработку приложений только для Windows 95. Ниже на рис. 12.8 показано как разбивается память на разделы (partitions) в адресном пространстве процесса под управлением Windows NT. Разделы будем рассматривать, двигаясь сверху вниз, от старших адресов к младшим. Верхнюю половину памяти (от 2 Гбайт до 4 Гбайт) система использует для своих нужд. Сюда она грузит свое ядро (kernel) и драйверы устройств. При попытке обратиться к адресу памяти из этого диапазона возникает исключительная ситуация нарушения доступа и система закрывает приложение. Заметьте, что половину памяти у нас отняли только из-за того, что иначе не удалось добиться совместимости с процессором MIPS R4000, которому нужна память именно из этого раздела. Следующий небольшой раздел (64 К) также резервируется системой, но никак ей не используется. При попытке обращения к этой памяти возникает нарушение доступа, но приложение не закрывается. Система просто выдает сообщение об ошибке. Большинство из вас знают, что потеря контроля над указателем в программе на языке С или C++ может привести к ошибкам такого рода. Следующие (почти) 2 Гбайт отданы в собственность процесса. Сюда загружаются исходный код приложения (ехе-модуль), динамические библиотеки (dll), здесь также располагаются стеки потоков и области heap, в которых они черпают динамически выделяемую память. Последний маленький (64 К) раздел, так же как и третий раздел, не используется системой и служит в качестве ловушки «непослушных» (wild) указателей.
Рис. 12.8. Разделы адресного пространства процесса Примечание В системах Windows NT Server Enterprise Edition и Windows 2000 Advanced Server процессу доступны нижние 3 Гбайт и только 1 Гбайт резервируется системой. Любому Win32-nponeccy могут понадобиться объекты ядра Windows, а также ее подсистемы User или GDI. Они расположены в динамически подключаемых библиотеках: Kernel32.dll, User32.dll, Gdi32.dll и Advapi32.dll Эти библиотеки при необходимости подгружаются в верхнюю часть блока, доступного процессу. Общий объем памяти, который система может предоставить всем одновременно выполняемым процессам, равен сумме физической памяти RAM и свободного пространства па диске, которым может пользоваться специальный страничный файл (paging file). Страницей называется блок памяти (4 Кбайт для платформ х86, MIPS, PowerPC и 8 Кбайт для DEC Alpha), который является дискретным квантом (единицей измерения) при обмене с диском. Виртуальный адрес в пространстве процесса проецируется системой в эту динамическую страничную память с помощью специальной внутренне поддерживаемой структуры данных (page map). Когда система перемещает страницу в страничный файл, она корректирует page тар того процесса, который ее используют. Если системе нужна физическая память RAM, то она перемещает на диск те страницы, которые дольше всего не использовались. Манипуляции с физической памятью никак не затрагивают приложения, которые работают с виртуальными адресами. Они просто не замечают динамики жизни физической памяти. Функции API для работы с памятью (virtualAlloc и virtualFree) позволяют процессу получить страницы памяти или возвратить их системе. Процесс отведения памяти имеет несколько ступеней, когда блоки памяти постепенно проходят через определенные состояния. Страницы памяти в виртуальном адресном пространстве процесса могут пребывать в одном из трех возможных состояний. Таблица 12.2. Состояния страниц памяти в виртуальном адресном пространстве процесса
Память, которую процесс отводит, вызывая функцию virtualAlloc, доступна только этому процессу. Если какая-то DLL в пространстве процесса отводит себе новую память, то она размещается в пространстве процесса, вызвавшего DLL, и недоступна для других процессов, одновременно пользующихся услугами той же DLL. Иногда необходимо создать блок памяти, который был бы общим для нескольких процессов или DLL, используемых несколькими процессами. Для этой цели существует такой объект ядра системы, как файлы, проецируемые в память (file mapping). Два процесса создают два упомянутых объекта с одним и тем же именем, получают описатель (handle) объекта и работают с ним так, как будто этот объект находится в памяти. На самом деле они работают с одними и теми же страницами физической памяти. Заметьте, что эта память не является глобальной, так как она остается недоступной для других процессов. Кроме того, ей могут соответствовать различные виртуальные адреса в пространствах разных процессов, ее разделяющих. Если процессы намерены записывать в общую память, то во избежание накладок вы должны использовать синхронизирующие объекты ядра Windows (семафоры, мыотексы, события). Алгоритм работы с динамической памятью процесса довольно сильно отличается от привычного алгоритма работы с динамической памятью области heap в программах на языке C++. Там вы с помощью операции new отводите память определенного размера, работаете с ней и затем освобождаете ее операцией delete. Здесь необходимы более сложные манипуляции:
Кроме того, возможна операция блокирования страниц памяти в RAM, которая запрещает системе перемещать их в страничный файл подкачки (paging file). Есть функция, позволяющая определить текущее состояние диапазона страниц и изменить тип доступа к ним. Операционная система Windows NT представляет собой множество отдельных модулей (подсистем), которые разработаны с учетом двух фундаментальных принципов:
Первый принцип подразумевает, что каждая подсистема отвечает за отдельную функцию всей системы и все другие потоки — другие части ОС или приложения пользователя, общаются с ней с помощью одного и того же хорошо продуманного интерфейса. Реализация принципа делает невозможными какие-то другие способы (back doors) доступа к критическим для функционирования системы структурам данных. Кроме того, такой подход дает возможность легко производить усовершенствование (upgrade) системы, так как подсистемы, удовлетворяющие заранее известному интерфейсу, можно заменять без какого-либо ущерба для системы. Для оценки важности второго принципа необходимо пояснить суть режимов выполнения команд kernel mode и user mode. В режиме ядра (kernel mode) вся память доступна и все команды выполнимы. Это привилегированный режим по сравнению с режимом user mode, когда система проверяет права доступа потока при каждом его обращении к памяти. Режим выполнения user mode значительно более надежен, но требует дополнительных затрат, которые снижают общую производительность процесса. В литературе режим ядра иногда называют режимом супервизора или режимом Ring(). Степени защиты памяти называют кольцами, а нулевое кольцо обозначает самый привилегированный аппаратный уровень. Вы можете встретить также обозначения PL=0 (Privilege Level) для kernel mode и PL = 3 для user mode. Если операционная система выполняет первый принцип и большинство ее модулей выполняется в режиме user mode, то говорят, что ОС является риге microkemel-системой. Возможны две версии перевода: «имеет чистое микроядро» и «настоящая microkernel-система». Если система удовлетворяет только первому принципу, то ее называют macrokernel OS. Большинство коммерческих ОС не выполняет второй принцип, так как они хотят быть быстрыми. Windows сразу примкнула к сторонникам microkernel OS, так как здесь соображения надежности поставлены на более высокое место. На рис. 12.9 приведена схема, иллюстрирующая архитектуру (состав подсистем) Windows NT. Подсистема Win32 Subsystem состоит из пяти модулей:
Рис. 12.9. Архитектура Windows Каждый компонент расположен в отдельном DLL-файле. Все они выполнялись в режиме user mode. Однако теперь (в NT 4.0) большинство подсистем выполняется в режиме kernel mode. При этом утверждается, что при переносе блоков из области user mode в область kernel mode надежность системы не снижается благодаря особым усилиям компании Microsoft, которая проявляет особую осторожность при создании такой части ОС, как GDD (Graphics Device Olivers). Примечание Вы знаете, что многие OEM-драйверы (Original Equipment Manufacturers) пишутся не в стенах компании, а другими разработчиками. Выполнение кодов этих, возможно, содержащих ошибки драйверов в режиме kernel mode, когда нет преград, может обрушить всю систему. Разработчики системы утверждают, что Windows NT является удивительно модульной и инкапсулированной системой, то есть слабозависящей от неожиданных изменений ситуации. Например, она не зависит от размера страницы page-файла. При загрузке системы, точнее, выполнении модуля NTDetect.com, который вы можете видеть в корневом каталоге системного диска, она определяет оптимальный размер страницы. Размер зависит от архитектуры процессора, то есть конкретной платформы. Система, например, может переключиться с размера 4К на 16К. При этом она продолжает надежно работать, несмотря на достаточно радикальную перемену в своей архитектуре. Функции некоторых подсистем: Virtual Memory Manager (Менеджер виртуальной памяти), Process Manager (Менеджер процессов) мы уже пояснили. Process Manager, кроме рассмотренных функций обеспечивает вместе с Virtual Memory Manager и Security Model (Модель защиты) защиту процессов друг от друга. Подсистема Object Manager (Менеджер объектов) создает, управляет и уничтожает объекты Windows NT Executive. Это абстрактные типы данных, используемые для представления таких ресурсов системы, как файлы, директории, разделяемые сегменты памяти, процессы, потоки, глобальное пространство имен и др. Благодаря модульной структуре подсистемы в нее могут быть легко добавлены и другие новые объекты. I/O Manager (Менеджер ввода-вывода) состоит из серии компонентов, таких как файловая система, сетевой маршрутизатор и сервер, система драйверов устройств, менеджер кэша. Стандартный интерфейс позволяет одинаковым образом общаться с любым драйвером. Здесь в полной мере проявляются преимущества многослойной (multi-layered) архитектуры. Много слов сказано в литературе и на конференциях про Security Reference Monitor (Монитор обращений к системе безопасности), но эта тема далеко не всем интересна. Почему-то она абсолютно не захватывает и мое воображение, хотя я понимаю, что тема может оказаться жизненно важной для тех, кому есть, что скрывать. Hardware Abstraction Layer (Аппаратный уровень абстракции) — HAL является изолирующим слоем между программным обеспечением, поставляемым разными производителями, и более высокими абстрактными слоями ОС. Благодаря HAL различные типы устройств выглядят одинаково с точки зрения системы. При этом убирается необходимость подстройки системы при введении новых устройств. При проектировании HAL была поставлена цель — создать процедуры, которые позволят общаться только с драйвером устройства, чтобы можно было управлять самим устройством в рамках любой платформы. Приложения и защищенные подсистемы взаимодействуют по типу клиент-сервер. Приложения (клиенты) запрашивают подсистемы (серверы) о необходимости выполнить какой-то сервис. При этом клиенты и серверы общаются посредством строго определенной последовательности сообщений. Такой стиль называется Inter-Process Communications (IPC — Обмен данными между процессами), и он имеет форму либо местных вызовов процедур Local Procedure Call (LPC), либо удаленных вызовов — Remote Procedure Call (RPC). Если и клиент, и сервер расположены в одном компьютере, TO Windows NT Executive использует LPC — оптимизированную разновидность общепринятого стандарта RPC, который действует между клиентами и серверами, расположенными в пределах одной сети компьютеров. Стандарт RPC позволяет обмениваться услугами с серверами, работающими на других платформах, например из UNIX-окружения. В современном операционном окружении программист не может быть уверен и не должен полагаться на то, что коды его программы будут выполняться в тон же последовательности, в какой они написаны. Выполнение одной из функций программы может быть остановлено системой и возобновлено позднее, причем это может произойти даже при выполнении тела какого-либо цикла. При проектировании многопотоковых приложений следует иметь в виду, что ресурсы, разделяемые потоками (блоки памяти или файлы), можно неосознанно повредить. Чтобы показать, как это происходит, рассмотрим пример, который приведен в книге Jesse Liberty «Beginning Object-Oriented Analysis and Design with C++» (Дж. Либерти «Начало объектно-ориентированного анализа и проектирования с помощью C++»), доступной в MSDN. Представьте себе пассажирский авиалайнер в полете, а в нем такой разделяемый всеми ресурс, как туалетная комната. Создатели самолета предполагали, что только одна персона может занимать эту комнату. Первый, кто ее занял, закрывает (lock) доступ к пей для всех остальных. Следующий пассажир, желающий воспользоваться этим ресурсом, может либо терпеливо ожидать освобождения, либо по истечении какого-то времени (time out) вернуться на свое сиденье и продолжать заниматься тем, чем он был занят до этого события. Решение о том, что выбрать и как долго ждать, принимает пассажир. Блокирование ресурса порождает неэффективное проведение времени второго пассажира как ожидающего очереди, так и избравшего другую тактику. Возвращаясь к многопотоковым процессам, отметим, что если не блокировать ресурс, то становится возможным повреждение данных. Представьте, что один поток процесса проходит по записям базы данных, повышая зарплату каждому сотруднику на 10%, а другой поток в это же время изменяет почтовые индексы в связи с введением нового стандарта. Согласитесь с тем, что разумно совместить эти две работы в одном процессе с целью повышения производительности. Что может произойти, если не блокировать доступ к записи при ее модификации? Первый поток прочел запись (все ее поля), и занят вычислением повышения (предположим, с $80 000 до $85 000). В это время второй поток читает эту же запись с целью изменения почтового индекса. В этой ситуации может произойти следующее: первый поток сохраняет измененную запись с новым значением зарплаты, а второй, возвращая запись с измененным индексом, реставрирует значение зарплаты и данный сотрудник останется без повышения. Это происходит по причине того, что оба потока не могут обратиться к части записи и поэтому работают со всей записью, хотя модифицируют только отдельные ее поля. Для того чтобы исключить подобный сценарий, автор многопотокового приложения должен решать проблему синхронизации при попытке одновременного доступа к разделяемым ресурсам. Если говорить о файлах с совместным доступом, то сходная ситуация может возникнуть и при столкновении различных процессов, а не только потоков одного процесса. Разработчика в этом случае уже не устроит стандартный способ открытия файла. Например1:
//======= Создаем объект класса CFile
CFile file;
// ====== Строка с именем файла
CString fn("MyFile.dat");
//===== Попытка открыть файл для чтения
if ( ! file.Open(fn,CFile::modeRead))
{
MessageBox ("He могу открыть файл "+fn, "Ошибка");
return;
}
Он должен писать код с учетом того, что файл может быть заблокирован какое-то время другим процессом. Если следовать уже рассмотренной тактике ожидания ресурса в течение какого-то времени, то надо создать код вида:
bool CMyWnd::TryOpen()
//====== Попытка открыть файл и внести изменения
CFile file;
CString fn("MyFile.dat"), Buffer;
//===== Флаг первой попытки
static bool bFirst = true;
if (file.Open (fn, CFile:: modeReadWrite I CFile::shareExclusive))
{
// Никакая другая программа не сможет открыть
// этот файл, пока мы с ним работаем
int nBytes = flie.Read(Buffer,MAX_BYTES);
//==== Работаем с данными из строки Buffer
//==== Изменяем их нужным нам образом
//==== Пришло время вновь сохранить данные
file.Write(Buffer, nBytes);
file. Close ();
//==== Начиная с этого момента, файл доступен
//==== для других процессов
//==== Если файл был открыт не с первой попытки,
//==== то выключаем таймер ожидания
if (IbFirst)
KillTimer(WAIT_ID);
//===== Возвращаем флаг успеха
return bFirst = true;
}
//====== Если не удалось открыть файл
else
if (bFirst) // и эта неудача — первая,
//===== то запускаем таймер ожидания
SetTiraer(WAIT_ID, 1000, 0);
//===== Возвращаем флаг неудачи
return bFirst = false;
}
В другой функции, реагирующей на сообщения таймера, называемой, как вы знаете, функцией-обработчиком (Message Handler), надо предусмотреть ветвь для реализации выбранной тактики ожидания:
//====== Обработка сообщений таймера
void CMyWnd::OnTimer(UINT nID)
{
//====== Счетчик попыток
static int iTrial = 0;
//====== Переход по идентификатору таймера
switch (nID)
{
//== Здесь могут быть ветви обработки других таймеров
case WAIT_ID:
//====== Если не удалось открыть
if (ITryOpenO)
{
//===== и запас терпения не иссяк,
if (++iTrial < 10)
return; // то продолжаем ждать
//=== Если иссяк, то сообщаем о полной неудаче
else
{
MessageBox ("Файл занят более 10 секунд",
"Ошибка"); //====== Отказываемся ждать
KillTimer(WAIT_ID);
//====== Обновляем запас терпения
iTrial = 0;
}
}
}
}
Существуют многочисленные варианты рассмотренной проблемы, и в любом случае программист должен решать их, например путем синхронизации доступа к разделяемым ресурсам. Большинство коммерческих систем управления базами данных умеют заботиться о целостности своих данных, но и вы должны обеспечить целостность данных своего приложения. Здесь существуют две крайности: отсутствие защиты или ее слабость и избыток защиты. Вторая крайность может создать низкую эффективность приложения, замедлив его работу так, что им невозможно будет пользоваться. Например, если в примере с повышением зарплаты первый поток заблокирует-таки доступ к записи, но затем начинает вычислять новое значение зарплаты, обратившись к источнику данных о средней (в отрасли) зарплате по всей стране. Такое решение проблемы может привести к ситуации, когда второй поток процесса, который готов корректировать эту же запись, будет вынужден ждать десятки минут. Одним из более эффективных решений может быть такое: первый поток читает запись, вычисляет прибавку и только после этого блокирует, изменяет и освобождает запись. Такое решение может снизить время блокирования до нескольких миллисекунд. Однако защита данных теперь не сработает в случае, если другой поток поступает также. Второй поток может прочитать запись после того, как ее прочел первый, но до того, как первый начал изменять запись. Как поступить в этом случае? Можно, например, ввести механизм слежения за доступом к записи, и если к записи было обращение в интервале между чтением и модификацией, то отказаться от модификации и повторить всю процедуру вновь. Примечание Каждое решение создает новые проблемы, а поиск оптимального баланса ложится на плечи программиста, делая его труд еще более интересным. Кстати, последнее решение может вызвать ситуацию, сходную с той, когда два человека уступают друг другу дорогу. Отметьте, что решение вопроса кроется в балансе между производительностью (performance) и целостностью данных (data integrity). В системе с преимущественной многозадачностью ноток может быть прерван в любой момент. Обычно перед выполнением очередной машинной команды система смотрит, есть ли прерывание. Если есть и приоритет его достаточно высок, то текущая команда не выполняется, а система переходит в режим обработки прерывания. Если программа написана без учета этого обстоятельства (not thread-safe), то последствия могут быть неожиданными. Например, если поток проверяет значение какого-то глобального флага и в зависимости от его значения выполняет разветвление, то возможна ошибка из-за того, что флаг мог быть изменен другим потоком, перехватившим управление в промежутке между этими двумя командами. Для создания thread-safe-прмложешт программист должен уметь синхронизировать доступ к критическим объектам так, чтобы один поток не портил работу другого. Важным понятием, которое имеет отношение к рассматриваемой проблеме и используется при описании алгоритмов управления источниками данных, является транзакция. Представьте, что один клиент банка производит депозит чека, который получен им от другого клиента. При выполнении этой операции нормально функционирующая система должна либо изменить оба счета, либо оставить все без изменений. Если на счету клиента, выписавшего чек, есть указанная сумма, то этот счет уменьшается, а счет второго клиента увеличивается. Если указанной суммы на счету первого клиента не оказалось, то оба счета должны остаться без изменений. Идея транзакции заключается в том, что после проведения изменений в записях базы данных все они либо принимаются (committed), либо отвергаются (rolled-back или aborted). Транзакция — это множество операций, которые выполняются либо все, либо ни одна. Транзакция представляет собой последовательность операций над БД (базой данных), рассматриваемых СУБД как единое целое и необходимых для поддержания ее логической целостности. То свойство, что каждая транзакция начинается при целостном состоянии БД и оставляет это состояние целостным после своего завершения, делает очень удобным использование этого понятия как единицы активности пользователя по отношению к БД. Для поддержки многозадачности требуются следующие механизмы обработки данных:
Одним из основных требований к СУБД является надежность хранения данных во внешней памяти. Под надежностью хранения понимается то, что СУБД должна быть в состоянии восстановить последнее согласованное состояние БД после любого аппаратного или программного сбоя. Обычно рассматриваются два возможных вида аппаратных сбоев: так называемые мягкие сбои, которые можно трактовать как внезапную остановку работы компьютера, например аварийное выключение питания, и жесткие сбои, характеризуемые потерей информации на носителях внешней памяти. Примерами программных сбоев могут быть:
Во всех случаях придерживаются стратегии «упреждающей» записи в журнал, так называемого протокола WAL — Write Ahead Log. Она заключается в том, что запись об изменении любого объекта БД должна попасть во внешнюю память журнала раньше, чем измененный объект попадет во внешнюю память основной части БД. Известно, что если в СУБД корректно соблюдается протокол WAL, то с помощью журнала можно решить все проблемы восстановления БД после любого сбоя. Выше мы рассмотрели, как потоки одного процесса могут вступить в конфликт и испортить работу друг друга. Одной из задач программиста является обеспечить невозможность такого сценария. Другими возможными неприятностями могут быть: рассинхронизация (race conditions) и тупиковая ситуация (deadlock). Первая может произойти, когда успех одной операции зависит от успеха другой, но обе они не синхронизированы друг с другом. Предположим, что один поток процесса подготавливает принтер, а другой ставит задание на печать (print job) в очередь. Если потоки не синхронизированы и первый из них не успеет выполнить свою работу до того, как начнется печать, то мы получим сбой. Примечание Но в каком-то количестве случаев все пройдет гладко. Такой тип ошибок очень неприятен, так как в процессе отладки ее нельзя уверенно и многократно воспроизводить. Рассинхронизация порождает ненадежность —тип ошибок, который большинство программистов всего мира ненавидит. В MSDN, но, к сожалению, не в литературе, вы часто можете встретить упоминания о коварстве irreprodudble bugs (невоспроизводимые ошибки). Суверенностью можно сказать, что книга под названием «Технологии борьбы с ошибками» была бы бестселлером. Тупиковая ситуация создается, когда один поток ждет завершения второго, а второй ждет завершения первого. Представьте, что один поток реализует такую функцию:
Обратите внимание на то, что освобождение блокировок происходит в обратном порядке. Именно так следует поступать при работе с записями базы данных и всеми объектами ядра Windows. Предположим далее, что второй поток реализует функцию начисления месячного процента и он делает те же действия, что и первый, но порядок блокирования и освобождения записей обратный. Оба потока по отдельности функционируют вполне надежно. В процессе работы возможен следующий сценарий: первый поток блокирует запись, идентифицирующую клиента, затем второй блокирует запись, описывающую его счет. После этого оба ждут освобождения записей, блокированных друг другом. Если ожидание реализовано разработчиком в виде бесконечного цикла, то мы его получили. Это тупиковая ситуация, или deadlock. Существует несколько стратегий, которые могут применяться, чтобы разрешать описанные проблемы. Наиболее распространенным способом является синхронизация потоков. Суть синхронизации состоит в том, чтобы вынудить один поток ждать, пока другой не закончит какую-то определенную заранее операцию. Для этой цели существуют специальные синхронизирующие объекты ядра операционной системы Windows. Они исключают возможность одновременного доступа к тем данным, которые с ними связаны. Их реализация зависит от конкретной ситуации и предпочтений программиста, но все они управляют потоками процесса по принципу: «Не все сразу, по одному, ребята». MFC предоставляет несколько классов, реализующих механизмы синхронизации. Прежде всего отметим, что хорошо спроектированный {thread-safe) класс не должен требовать особых затрат для синхронизации работы с ним. Все делается внутри класса его методами. Обычно при создании надежного класса в него изначально внедряют какой-либо синхронизирующий объект. Например, критическую секцию, событие, семафор, мъютекс или ожидаемый таймер. Иерархию классов MFC для поддержки синхронизирующих объектов можно увидеть в MSDN:
Рис. 12.10. Иерархия классов синхронизации Все перечисленные классы, кроме критической секции, принадлежат ядру Windows. Вы знаете, что Windows-приложение использует множество и других объектов:
При работе с объектами этих подсистем надо соблюдать определенные правила. Но при работе с объектами ядра правила особые. Вам следует познакомиться с общими положениями об использовании объектов ядра системы. Они похожи на стандарты СОМ.
Синхронизация потоков развивается по такому сценарию. При засыпании одного из них операционная система перестает выделять ему кванты процессорного времени, приостанавливая его выполнение. Прежде чем заснуть, поток сообщает системе то особое событие, которое должно разбудить его. Как только указанное событие произойдет, система возобновит выдачу ему квантов процессорного времени и ноток вновь получит право на жизнь. Потоки усыпляют себя до освобождения какого-либо синхронизирующего объекта с помощью двух функций: DWORD WaitForSingleObject (HANDLE hObject, DWORD dwTimeOut); DWORD WaitForMultipleObjects(DWORD nCount, CONST HANDLE* lpHandles, BOOL bWaitAll, DWORD dwTimeOut); Первая функция приостанавливает поток до тех пор, пока или заданный параметром hObject синхронизирующий объект не освободится, или пока не истечет интервал времени, задаваемый параметром dwTimeOut. Если указанный объект в течение заданного интервала не перейдет в свободное состояние, то система вновь активизирует поток и он продолжит свое выполнение. В качестве параметра dwTimeOut могут выступать два особых значения: Таблица 12.3. Значения, выступающие в качестве параметра dwTimeOut
В соответствии с причинами, по которым поток продолжает выполнение, функция WaitForSingleObject может возвращать одно из следующих значений: Таблица 12.4. Возвращение значений функцией WaitForSingleObject
Функция WaitForMultipleObjects задерживает поток и в зависимости от значения флага bWaitAll ждет одного из следующих событий:
Это самые простые объекты ядра Windows, которые не снижают общей эффективности приложения. Пометив блок кодов в качестве critical section, можно синхронизировать доступ к нему от нескольких потоков. Сначала следует объявить глобальную структуру; CRITICAL_SECTION cs; затем инициализировать ее вызовом функции Initial! zeCri ticalSection (&cs);. Обычно это делается один раз, перед тем как начнется работа с разделяемым ресурсом. Далее надо поместить охраняемую часть программы внутрь блока, который начинается вызовом функции EnterCriticalSection и заканчивается вызовом LeaveCriticalSection:
EnterCriticalSection (&cs);
{
//====== Здесь расположен охраняемый блок кодов
}
LeaveCriticalSection (Scs);
Функция EnterCriticalSection, анализируя поле структуры cs, которое является счетчиком ссылок, выясняет, вызвана ли она в первый раз. Если да, то функция увеличивает значение счетчика и разрешает выполнение потока дальше. При этом выполняется блок, модифицирующий критические данные. Допустим, в это время истекает квант времени, отпущенный данному потоку, или он вытесняется более приоритетным потоком, использующим те же данные. Новый поток выполняется, пока не встречает функцию EnterCriticalSection, которая помнит, что объект cs уже занят. Новый поток останавливается (засыпает), а остаток процессорного времени передается другому потоку. Функция LeaveCriticalSection уменьшает счетчик ссылок на объект cs. Как только поток покидает критическую секцию, счетчик ссылок обнуляется и система будит ожидающий поток, снимая защиту секции кодов. Критические секции применяются для синхронизации потоков лишь в пределах одного процесса. Они управляют доступом к данным так, что в каждый конкретный момент времени только один поток может их изменять. Когда надобность в синхронизации потоков отпадает, следует вызвать DeleteCriticalSection (&cs);. Эта функция освобождает все ресурсы, включенные в критическую секцию. Критические секции просты в использовании и обладают высоким быстродействием, но не обладают гибкостью в управлении. Нет, например, возможности установить время блокирования или присвоить имя критической секции для того, чтобы два разных процесса могли иметь с ней дело. Оба эти недостатка можно устранить, если использовать такой объект ядра, как mutex. Термин mutex происходит от mutually exclusive (взаимно исключающий). Этот объект обеспечивает исключительный (exclusive) доступ к охраняемому блоку кодов. Например, если несколько процессов должны одновременно работать с одним и тем же связным списком, то на время выполнения каждой операции: добавления, удаления элемента или сортировки, следует заблокировать список и разрешить доступ к нему только одному из процессов. Для синхронизации потоков разных процессов следует объявить один общедоступный объект класса CMutex, который будет управлять доступом к списку. Мыо-текс предоставляет доступ к объекту любому из потоков, если в данный момент объект не занят, и запоминает текущее состояние объекта. Если объект занят, то мьютекс запрещает доступ. Однако можно подождать освобождения объекта с помощью функции WaitForSingleObject, в которой роль управляющего объекта выполняет тот же мьютекс. Типичная тактика использования такова. Объект CMutex mutex; необходимо объявить заранее. Обычно он является членом thread-safe-класса. В точке, где необходимо защитить код, создается объект класса CSingleLock, которому передается ссылка на мьютекс. При попытке включения блокировки вызовом метода Lock надо в качестве параметра указать время (в миллисекундах), в течение которого следует ждать освобождения объекта, охраняемого мьютексом. В течение этого времени либо получим доступ к объекту, либо не получим его. Если объект стал доступен, то мы запираем его от других потоков и производим работу, которая требует синхронизации. После этого освобождаем блокировку. Если время ожидания истекло и доступ к объекту не получен, то обработка этой ситуации (ветвь else) целиком в нашей власти. Если задать ноль в качестве параметра функции Lock, то ожидания не будет. Напротив, можно ждать неопределенно долго, если передать константу INFINITE. Другой процесс, если он знает, что существует мьютекс с каким-то именем, может сделать этот объект доступным для себя, открыв уже существующий мьютекс. При вызове функции OpenMutex система сканирует существующие объекты-мьютексы, проверяя, нет ли среди них объекта с указанным именем. Обнаружив таковой, она создает описатель объекта, специфичный для данного процесса. Теперь любой поток данного процесса может использовать описатель в целях синхронизации доступа к какому-то коду или объекту. Когда мьютекс становится ненужным, следует освободить его вызовом CloseHandle(HANDLE hObject); где hObject — описатель мьютекса. Когда система создает мьютекс, она присваивает ему имя (строка в стиле С). Это имя используется при совместном доступе к мыотексу нескольких процессов. Если несколько потоков создают объект с одним и тем же именем, то только первый вызов приводит к созданию мьютекса. Имя используется при совместном доступе нескольких процессов. Если оно совпадает с именем уже существующего объекта, конструктор создает новый экземпляр класса CMutex, который ссылается на существующий мьютекс с данным именем. Если имя не задано (IpszName равен NULL) мьютекс будет неименованным, и им можно пользоваться только в пределах одного процесса. С любым объектом ядра сопоставляется счетчик, фиксирующий, сколько раз данный объект передавался во владение потокам. Если поток вызовет, например, CSingleLock: :Lock() ИЛИ WaitForSingleObject () ДЛЯ уже принадлежащего ему объекта, он сразу же получит доступ к защищаемым этим объектом данным, так как система определит, что поток уже владеет этим объектом. При этом счетчик числа пользователей объекта увеличится на 1. Теперь, чтобы перевести объект в свободное состояние, потоку необходимо соответствующее число раз вызвать CSingleLock::Unlock() ffilHReleaseMutex() . Функции EnterCriticalSection и LeaveCriticalSection действуют по отношению к критическим секциям аналогичным образом. Объект-мьютекс отличается от других синхронизирующих объектов ядра тем, что занявшему его потоку передаются права на владение им. Прочие синхронизирующие объекты могут быть либо свободны, либо заняты и только, а мьютексы способны еще и запоминать, какому потоку они принадлежат. Отказ от мьютекса происходит, когда ожидавший его поток захватывает этот объект, переводя его в занятое состояние, а потом завершается. В таком случае получается, что мьютекс занят и никогда не освободится, поскольку другой поток не сможет этого сделать. Система не допускает подобных ситуаций и, заметив, что произошло, автоматически переводит мьютекс в свободное состояние. В некоторых случаях потоку необходимо ждать, пока другие-потоки не завершат выполнение каких-то операций или не произойдет какое-либо событие (UI-событие User Interface), то есть событие, инициированное пользователем. В качестве примера, предположим, что имеется 50 выходных телефонных портов и каждый из них управляется отдельным потоком. Пусть класс ccaller для управления соединениями (звонками) уже разработан. Есть также выделенный поток, который управляет всеми портами и отслеживает их статус. Допустим, что до того, как сделать какой-нибудь звонок (call), надо инициализировать все потоки. Тогда алгоритм ожидания множественного события может выглядеть так, как показано ниже. В рассматриваемом фрагменте предполагается, что объект СЕ vent m_nTotalCallers; уже существует и должным образом инициализирован:
//======= Цикл по всем портам
for (int i = 0; i<m_nTotalCallers; i++)
{
//=== Предварительные установки и создание потоков
CCaller * pCaller = new CCaller(Лпараметры*/);
BOOL bRc = pCaller->CreateThread();
}
//======= Блокировка
CSingleLock lock (Sm_CallersReadyEvent) ;
//======= Попытка дождаться события
if (lock.Lock(WAIT_VERY_LONG_TIME))
{
for (i=0; i<m_nTotalCallers; i++)
{
//===== Совершение соединений (звонков)
)
lock.Unlock();
}
else // Отказ ждать
{
//====== Обработка исключения
}
Класс CEvent представляет функциональность синхронизирующего объект ядра (события). Он позволяет одному потоку уведомить (notify) другой поток о том, что произошло событие, которое тот поток, возможно, ждал. Например, поток, копирующий данные в архив, должен быть уведомлен о том, что поступили новые данные. Использование объекта класса CEvent позволяет справиться с этой задачей максимально быстро. Существуют два типа объектов: ручной (manual) и автоматический (automatic). Ручной объект начинает сигнализировать, когда будет вызван метод SetEvent. Вызов ResetEvent переводит его в противоположное состояние. Автоматический объект класса CEvent не нуждается в сбросе. Он сам переходит в состояние nonsignaled, и охраняемый код при этом недоступен, когда хотя бы один поток был уведомлен о наступлении события. Объект «событие» (CEvent) тоже используется совместно с объектом блокировка (CSingleLock или CMultiLock). Семафором называется объект ядра, который позволяет только одному процессу или одному потоку процесса обратиться к критической секции — блоку кодов, осуществляющему доступ к объекту. Серверы баз данных используют их для защиты разделяемых данных. Классический семафор был создан Dijkstra, который описал его в виде объекта, который обеспечивает выполнение двух операций Р и V. Первая литера является сокращением голландского слова Proberen, что означает тестирование, вторая — обозначает глагол Verhogen, что означает приращивать (increment). Первая операция дает доступ к ресурсу, вторая — запрещает доступ и увеличивает счетчик объектов, его ожидающих. Различают два основных использования семафоров: защита критической секции и обеспечение совместного доступа к ресурсу. В качестве примера может служить критическая секция в виде функции, осуществляющей доступ к таблице базы данных.. Другим примером может служить реализация списка операционной системы, который называется process control blocks (PCBs). Это список указателей на активные процессы. В каждый конкретный момент времени только один поток ядра системы может изменять этот список, иначе будет нарушена семантика его использования. Семафор может быть использован также для управления перемещением данных (data flow) между п производителями и m потребителями. Существует много систем, имеющих архитектуру типа data flow. В них выход одного блока функциональной схемы целиком поступает на вход другого блока. Когда потребители хотят получить данные, они выполняют операцию типа Р. Когда производители создают данные, они выполняют операцию типа V. Традиционно семафоры создавались как глобальные структуры, совместно с глобальными API-функциями, реализующими операции Р и V. Теперь семафоры реализуются в виде класса объектов. Обычно абстрактный класс Семафор определяет чисто виртуальные функции типа Р и V. От него производятся классы, реализующие два указанных типа семафоров: защита критической секции и обеспечение совместного доступа к ресурсу. В смысле видимости оба типа семафоров могут быть объявлены либо глобально во всей операционной системе, либо глобально в пространстве процесса. Первые видны всем процессам системы и, следовательно, могут ими управлять. Вторые действуют только в пространстве одного процесса и, следовательно, могут управлять его потоками. Сам семафор ничего не знает о том, что он защищает. Ему обычно передается ссылка на объект класса, который хочет использовать критическую секцию, и он либо дает доступ к объекту, либо подвешивает (suspends) объект до тех пор, пока доступ не станет возможным. Важно отметить, что при реализации семафоров и других объектов ядра используют специальные атомарные команды (atomic steps), которые не прерываются системой. Блокировки — это семафоры, которые приспособлены для двух операций транзакции (commit и abort). Они используются для обеспечения последовательного доступа конкурирующих потоков или процессов к критическим секциям. Обычно в базах данных блокируется некоторое множество данных (range of items), так как блокировка одного элемента более накладна. Представьте такой запрос: Select * from Customer where country = Russia and city = "Moscow"; Чтобы защитить данные от рассмотренных выше неприятностей, надо заблокировать все строки таблицы, которые удовлетворяют указанному критерию поиска. Такой способ защиты, оказывается, обладает побочным эффектом. Он может породить запись-призрак (phantom). Допустим, что в это же время другой поток процесса добавляет в ту же таблицу Customer (Клиент) новую запись и ее поля удовлетворяют тому же критерию (клиент из Мосвы). Она, конечно же, будет добавлена в таблицу, но для первого потока она является фантомом (не существует). Для того чтобы записи-фантомы не создавались, надо избегать блокирования отдельных записей. Альтернативой является блокировка всей таблицы. Но это решение приводит к снижению эффективности работы СУБД. Другим выходом является предикатная блокировка (predicate locking). Предикат мы определили в уроке, посвященном библиотеке шаблонов STL. Это функция, которая может принимать только два значения (false, true} или {0,1}. В нашем примере такая блокировка запомнит не только записи, которые существуют в таблице и удовлетворяют критерию, но и все несуществующие записи такого типа, то есть блокируется весь тип записей заданного типа. Поэтому второй поток процесса найдет таблицу закрытой и будет вынужден ждать окончания работы первого. Предикатные блокировки хороши, но достаточно накладны. Еще одной альтернативой являются прецизионные блокировки (precision locking). Они не закрывают доступ к записям, но обнаруживают конфликты, когда транзакция пытается прочесть или сохранить записи. Прецизионные блокировки более просты в реализации, но создают повышенный риск тупиковых ситуаций (deadlocks). До сих пор мы говорили о блокировках, которые имеют одинаковую гранулярность, то есть размер единицы блокируемых данных: таблица, запись или поле. Обычно запрос хочет иметь доступ ко всей таблице, в то время как изменения вносятся только в отдельные записи или даже только в отдельные поля записи. Разработчики механизмов синхронизации ищут оптимум между двумя взаимно противоположными устремлениями: обеспечить максимальную защиту и использовать минимальное число блокировок. Гранулярные блокировки ограничивают транзакции небольшим множеством определенных предикатов, которые образуют дерево. В корне дерева обычно находится предикат, который разрешает или запрещает доступ ко всей базе данных. На следующем уровне может быть предикат, возвращающий доступ к определенному сайту (site) распределенной базы данных. Следующий уровень связан с таблицей и т. д. вплоть до домена или поля. Блокировки, определенные предикатом какого-то уровня, блокируют все объекты, описываемые предикатом следующего уровня. Это свойство принадлежит всем деревьям. В связи с чем может возникнуть новая проблема. Допустим, что одна транзакция заблокировала базу на уровне записи, а другая в это же время блокирует базу на уровне таблицы. При этом первый поток не может ничего сделать, и вынужден ждать, а второй споткнется при попытке изменить запись, блокированную первой. Опять имеем deadlock. Это привело к разработке нового, более изощренного типа блокировок — целевые блокировки (intention locks). Их идея состоит в том, что при блокировке обозначается ее цель. Например, блокировка таблицы сообщает, что ее целью являются изменения на уровне записей. В этом случае устраняется возможность тупиковой ситуации рассмотренного выше типа. Например, для установки разделяемой блокировки (share lock) на уровне записей транзакция должна сначала установить целевые блокировки (intention locks) на всех уровнях, которые расположены ниже или выше, в зависимости от интерпретации дерева, то есть на уровне таблицы, на уровне базы данных или сайта, если база является распределенной. После этого можно произвести запрос на становку блокировки типа share-lock на уровне записей. Единственным способом выхода из тупиковой ситуации (deadlock) является снятие блокировки одним из потоков. Это означает прерывание или отказ от транзакции. Система может либо предупреждать захваты либо допускать их, но затем соответствующим образом обрабатывать. Оказалось, что стандартные протоколы работы с базами данных достаточно редко приводят к образованию захватов, поэтому было признано целесообразным допускать появление захватов при условии, что разработаны механизмы их обнаружения. Особую проблему составляет обнаружение захватов в распределенных базах данных, так как нет простого способа, с помощью которого один узел сети может узнать, какие блокировки наложены в данный момент другим узлом. Два технических приема используются для обнаружения тупиковой ситуации. Первый — это установка таймера перед совершением транзакции. Если время для ее совершения вышло, то транзакция прерывается, блокировка снимается, что дает возможность другому потоку или процессу закончить свою операцию. Это решение очень просто реализовать, но его недостатком является то, что врожденно медленные транзакции могут потерять шанс быть выполненными. Другим методом является создание специальной структуры данных, которая моделирует граф ожиданий (waits-for graph) — бинарное отношение ожидания между транзакциями. Узлами графа являются транзакции, а дугами — факты ожидания. Так, например, дуга (i, j) (из узла i в узел j) существует, если транзакция i ожидает освобождения блокировки, наложенной транзакцией j. Очевидно, что тупиковой ситуации в этой модели соответствует цикл. Отметьте, что" длина цикла (количество его дуг) может быть более двух. Алгоритмы обнаружения циклов в графах давно разработаны. Графы обычно хранятся в виде динамических списков, то есть каждый узел хранит список блокировок — указателей на транзакции, которые ему мешают. Сам список обычно защищен семафором. С целью экономии времени процессора детектор циклов включается лишь при необходимости или периодически. Цикл считается обнаруженным, если в списке транзакций, которые тормозят данную, присутствует транзакция, в списке которой есть указатель на исходную. Эту фразу, вероятно, придется прочесть несколько раз. Отметим, что библиотека классов MFC поддерживает механизмы синхронизации, но детали их реализации скрыты от разработчика. Тем не менее он может использовать их, не заботясь о деталях реализации. Главным требованием при этом, как и при работе с любыми другими объектами классов MFC, является соблюдение протокола, описанного в интерфейсе класса. К сожалению, время, отведенное для написания книги, закончилось и мне не удастся привести и описать примеры приложений, иллюстрирующих использование синхронизирующих объектов ядра Windows, хотя такие примеры разработаны и достаточно давно используются в вышеупомянутом учебном центре.
|
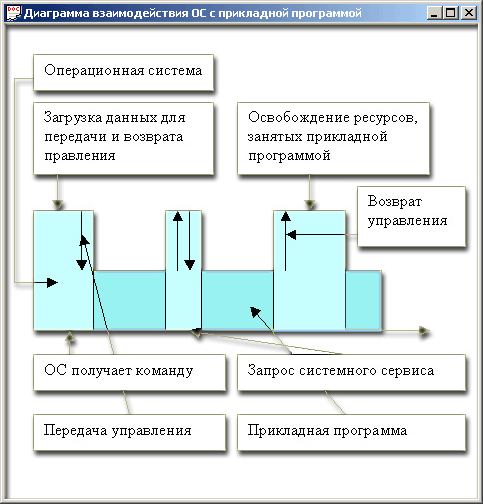



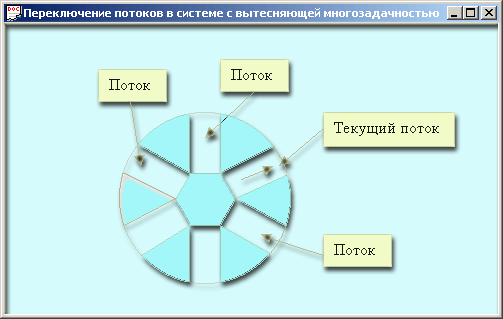


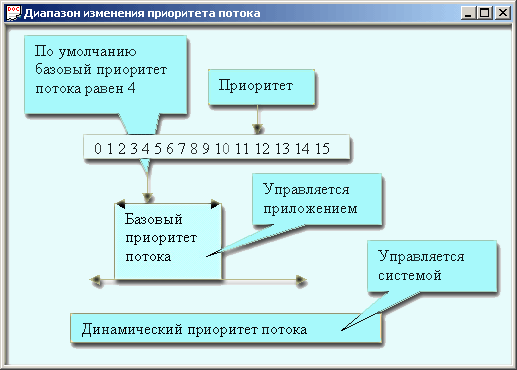
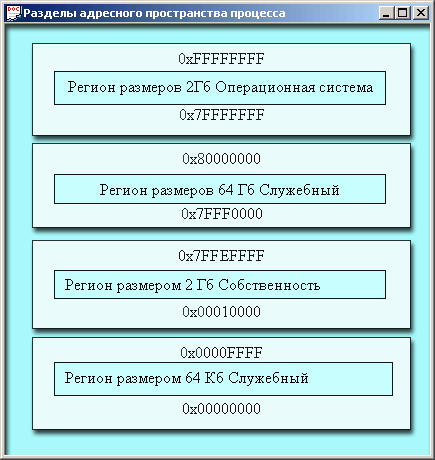

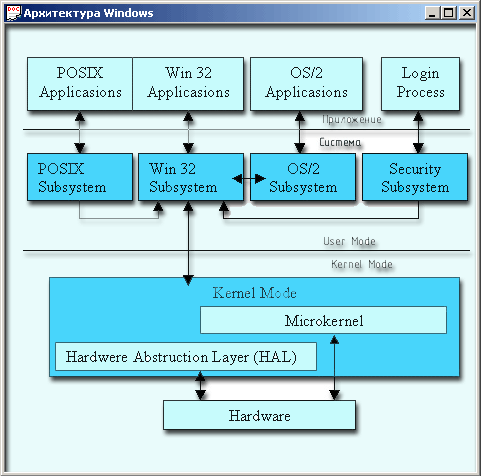
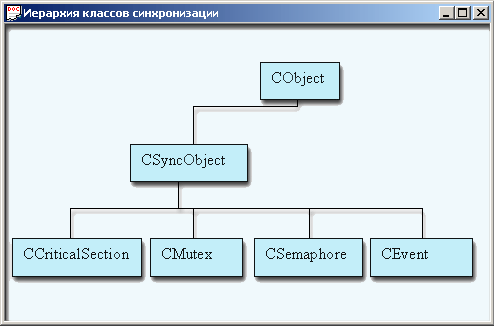


|